Kamus uses a database which contains all the information required by the
program, including the definitions for each word, lists of related words, lists
of affixes to look for when parsing, as well as grammatical information about
the different prefix, root and suffix combinations. This database will be
described in more detail later.
The overall structure of Kamus is shown in Figure 3, from which it can be seen
that there are four main sub-systems. The interface sub-system mediates
between the user and the rest of the program. For the X-Windows version of
Kamus, it creates the windows being used and manages them, as well as
retrieving the word from the user and returning the retrieved information. The
interface for the UNIX command-line version prompts for a word and returns the
information.
After the Interface sub-system obtains a word from the user, it is submitted to
the Parser for analysis. A list of suffixes and prefixes is retrieved from the
database and used to break down the word into its morphemes (i.e. prefix,
suffix, and root, as applicable). These morpheme(s) and the original word are
passed on to the Database Retriever. This searches the database to provide a
meaning for the word and a list of any synonyms. It also retrieves all of the
relevant grammatical information belonging to the word. Finally, all of the
information is displayed for the user. Note that the database itself is not
called from the interface sub-system. It is only used by the parser and the
database retriever to produce the required results.
Some aspects of the operation of the parser have already been discussed under
"Default Behaviour of Kamus". This Section presents a more complete
description.
The parser was developed to analyse the word and to produce as much grammatical
information as possible. Its role is to break down the word into the root,
prefix and suffix (as appropriate), since knowing these is a prerequisite for
successful later analysis.
The first thing the parser does when it is called is check to see whether the
word it has just been given is a root word. This is done by searching the
database for a match against words of type 'root'. If the whole word is found
as a root, then there is no need to go any further and the parser exits.
If the word given to the parser is not found as a root then it probably
contains more than one morpheme. On this assumption, a check is first made to
see if any of the known suffixes exist as part of the word. The list of
possible suffixes is retrieved from the database, and the word is checked
against them. If no match is found then the parser continues on to check for a
prefix. On the other hand, if a match is found then two possibilities remain -
either the word has a genuine suffix as part of its structure, or the base word
happens to contain the same set of characters as a suffix and the match is
spurious. To determine which of these is the case, the parser leaves the
purported suffix attached and checks for the existence of a prefix. The
concept here is that if a prefix is found then the parser separates it from the
whole word and checks to see if the remainder is a known root. If it is, the
suffix match must have been a spurious one and the word actually consists of a
prefix attached to a root that happens to contain the same letters as a suffix.
Alternatively, failure of this check is taken to mean that the suffix match is
genuine. In this case, the parser separates the (genuine) suffix from the rest
of the word and checks what is left for a prefix. Failure to find one means
that the original word consisted only of a root plus a suffix, whereas success
means that the original word consisted of a prefix, root and suffix combined
together.
This method of checking for a prefix whist in the middle of checking a suffix,
and then again and again (until a recognized root is found or no other
possibilities remain) is the way that Kamus provides its equivalent to the
back-tracking found in declarative languages like Prolog.
The main hurdle experienced in the development of the parser was dealing with
words that were special cases. After considering several solutions it was
decided that the parser should assume that if a word is not in the database,
then it complies with "normal" grammatical rules. The decomposition algorithm
described above implements this.
Another complication that arose while programming the parser concerned the
transformational grammar that characterizes prefixes and root words where the
initial letter is dropped. This concept was described earlier in relation to
Table 1 and the prefixes involved were mem- for the letter 'p',
meng- for the letter 'k', men- for the letter 't', and
meny- for the letter 's'. This situation was complicated further
because these prefixes may be attached to roots beginning with any letter, not
just those that are dropped. It therefore was not just a case of removing the
prefix, adding the dropped letter and then looking up the root.
To deal with these cases, Kamus first searches for and separates any prefix
from the word, and then looks for the remainder as a root in the database.
Success means that no dropped letter was involved, but failure could be because
of a dropped letter so this case is considered next. This entails adding the
appropriate dropped letter on to the beginning of the root and checking for the
modified root's existence in the database. If it is found, then the
decomposition process is complete and a dropped leading letter was involved.
If the modified root is not found then the added letter is removed, the
separated prefix replaced, and the reconstituted whole word checked for other
possible prefixes. This was done to deal with the me- class of
prefixes. For example, if a word begins with the letters meng there are
two possible outcomes from the parser. The first is that the word contains the
prefix meng-, and the other is that the word contains the prefix
me- and the root begins with 'ng'. Both of these may occur, so if one
decomposition does not result in a successful search, the other is tried.
There is a third outcome that might be considered, and that is a prefix of
men- with the root starting with 'g'. This, however, is not possible
since the prefix men- is only attached to words beginning with 't', 'c',
'd' or 'j'. And similarly for prefixes mem- and me-,
meny- and me-, and men- and me-. Kamus considers
these possiblities but, of course, does not succeed with these attempted
decompositions because the "roots" produced by them do not exist in the
supporting database.
A decision has been made to exclude as much grammatical information from the
actual code of the parser as possible. The code in the parser is written in
the form "when X occurs, do Y", but at compilation time, the actual contents of
X and Y are not known. At run time, X and Y are retrieved from the database
and placed into the 'shells' as required. Most of this grammatical information
has been stored in the database tables "prefix_list", "suffix_list" and
"replaced_by". This design decision should make future modifications to Kamus
to include other types of words easier since it will basically be a matter of
adding affixes to the lists in the database, and only rarely adding another
'shell' to the code.
The role of the database retriever is to retrieve the meaning of the selected
word in addition to other grammatical information. It receives the root, any
affixes found, plus the original word from the parser and, using this data, it
can obtain the meaning of the word through an embedded SQL interface between
the program and the database.
To provide all of the relevant grammatical information, the type of the root
(e.g. noun, adverb, etc.) and the structure of the word (e.g. root, prefix plus
root, etc) is retrieved. The structure of the word informs the program where
to look in the database. The program then retrieves the meaning of the
affix(es) based on the word's root type.
The database has been designed to contain all of the information specific to
the Indonesian language. That is, word meanings, grammatical information, as
well as lists of affixes and their meanings for various root types.
The design of the database can viewed as consisting of four main parts, the
part that shows how a word has other related words, and then how the different
combinations of affixes and the root can exist, that is root plus prefix, root
plus suffix and root plus prefix plus suffix.
An entity relationship diagram was constructed and converted into a relational
schema (which specifies the tables that are required to store the information).
The full entity relationship diagram can be found in Annex A. The rectangles
in this diagram represent entities, the things about which data is to be
stored. The diamond symbols represent relationships between the entities. For
example, the word ajak "has root type" transitive verb, where
transitive verb is one of the valid types of root. The ellipses on the
diagram are known as attributes. These specify the actual data items that are
recorded about the various entities, or relationships, of the database. As an
example, looking at the entity "prefix_list", we record the letters of each
prefix ("prefix"), its length ("length"), the letter dropped from the root when
it is attached, if any ("dropped_letter"), and its class ("class"). Finally,
the characters "1", "M" and "N" specify the cardinalities of the relationships
in the database. For example, a word can be of only one type (e.g. "noun") but
there will many words of the same type (e.g. there are many words that are
nouns).
There are six main tables in the database supporting Kamus, these being "word"
(to store the meaning of a word, the type of its root and the type of the word
as a whole), "related_words" (to store the synonyms), "root_suffix" (to store
the words of type root + suffix), "prefix_root" (to store the words of type
prefix + root), "prefix_root_suffix" (to store the words of type prefix + root
+ suffix) and "replaced_by" (to indicate which prefixes are replaced by which
and under what circumstances).
The entity "word" participates in three relationships, two with other entities
- namely "type of word", and "type of root", and one with itself - for related
words. The relationship with "word type" specifies the form of the word with
respect to the affixes. That is, whether it is a root, prefix +
root, root + suffix, or prefix + root + suffix. The
relationship with "root type" specifies the grammatical type of the root of the
word, e.g. noun, transitive verb, intransitive verb,
simple verb, adverb or adjective. The relevance of "word
type" and "root type" is that they are used to retrieve grammatical information
about the word to display to the user.
The relationship "related to" connects the entity "word" to itself. This
allows each particular word to be connected to other words that are either its
synonyms or related in some other way (such as a different grammatical form
with the same root). Words with the same root are included since there are
times when writing Indonesian that a linguist might know that he or she wants
to use a particular form of the root, but cannot think of which one. Kamus can
then be used to retrieve the root word, but in addition to synonyms it will
also provide other forms with the same root from which the linguist can
choose.
The bottom half of the entity relationship diagram is concerned with how the
affixes can be joined to particular types of root, and what effect the
conjunction will have on the meaning for each different type of root. It also
details the grammatical type of the whole word that results from the connection
(i.e. noun, adjective, etc).
The bottom right corner of the entity relationship diagram relates to prefixes.
This data is used by the parser to break down the word into its morphemes
(prefix, root and suffix). For each prefix that is stored there is the ability
to store what has been called a 'dropped letter', though of course this only
applies to a few of them (see Table 1). As described above, knowledge about
dropped letters is required by the parser to reconstruct the root after
removing a prefix that entails a dropped letter.
The entity "prefix_list" participates in a relationship "replaced by". This
deals with the passive form of transitive verbs. When transitive verbs are
used in their passive form the me- prefix is replaced by a di-
prefix. When parsing the word the parser needs to recognise that if the
di- prefix is part of the word, and the word is not a root in the
database, then the di- prefix needs to be replaced with the
corresponding me- prefix before further analysis. This is worked out by
looking at the first letter of the word after the di- prefix has been
removed since this will indicate which me- prefix is the appropriate
replacement. An interesting complication is that when the di- prefix is
used letters that are normally dropped with an me- prefix are
retained.
The database has been designed so that it can be upgraded to cater for the
whole Indonesian vocabulary. Although the prototype deals only with transitive
verbs, the database should be able to be easily modified to cope with other
types of words. In achieving this the parser component of Kamus may need to
have some extra rules added, and the database will need not only the extra
words themselves but also the other prefixes and suffixes of the language
outside of those used by the transitive verbs.
The list of words that has been stored in the database is mostly from
Langkah Baru [JoSt89], [John90]. These references were chosen so that
the list of transitive verbs obtained would provide a large enough selection of
vocabulary to demonstrate the prototype. Over six hundred root words were
chosen, resulting in more than fourteen hundred different combinations. It was
originally intended to go through the Echols and Shadily dictionary Kamus
Indonesia Inggris [EcSh89] to make the list more complete, but this was
not necessary in order to develop a working prototype so this task has been
left as an area for future development.
Not every transitive verb from Langkah Baru [JoSt89], [John90]
was used, and there may be some stored in the database that are not transitive
verbs. The reason for this is that there are no known Indonesian dictionaries
that specify the type of the word (i.e. transitive verb). Kamus Besar
[Kamu88] gives information about the root but does not distinguish between
the classes of verbs; nor does it give the type of the word when showing the
different forms of the roots. We have thus attempted to classify the verbs in
the prototype ourselves. If any further work is carried out on Kamus, the
grammatical information that has already been entered into the database will
have to be checked for correctness.
The synonyms for the prototype were obtained from Kamus Ungkapan
Indonesia-Inggris, which is an Indonesian-English Dictionary
[PoSu85a],[PoSu85b]. This also turned out to be a very time consuming task
since, although the dictionary would list one word as being a synonym for
another, it was not necessarily listed the other way around. Any synonyms
mentioned in the dictionary that were not part of the chosen vocabulary were
not included.
Table 2 shows several words that were put through Kamus along with the results
that were output. The first three words, membawa, memotong, and
mempertambangkan are words that exist in the database and, as can be
seen, they have been parsed correctly. The first is a 'normal' word where the
prefix is simply attached to the root without any modification. The second
involves a dropped letter since the root word begins with 'p' and the prefix is
mem (see Table 1). The third one demonstrates that Kamus treats two
prefixes joined together, such as memper, as one prefix. Mereka
is not a transitive verb and does not have any prefixes or suffixes but, since
it has not been entered into the database, Kamus has followed its default
behaviour (i.e. assumed that it follows the 'normal' syntactical rules) and has
parsed it into a prefix + root. The final word is not in the database either,
and nor is it a transitive verb. Kepandaian is actually a noun, but as
the affixes ke and an are used for transitive verbs as well,
Kamus has correctly parsed the word. This demonstrates that with the addition
of the correct affixes for other parts of the Indonesian language, Kamus can be
used to translate those words correctly as well.
Selected Word Prefix Root Suffix
membawa mem bawa
memotong mem potong
mempertambangkan memper tambang kan
mereka me reka
kepandaian ke pandai an
Table 2: Sample Results from Kamus.
The main limitations highlighted during the testing of the Kamus prototype
were:
a The user does not have the opportunity to select a word from a large
vocabulary in the database. Only 600 root words are stored together with 800
transitive verbs formed from these root words. Ideally, the database would
contain not only all of the transitive verbs, but the majority of the
Indonesian language. Kamus also does not have the ability to deal with
transitive verbs that contain a duplicated root, or two roots joined together,
or are using the shortened versions of the pronouns engkau and
aku.
b If information needs to be modified or added to the database, the user must
be familiar with the underlying Ingres database software. As this is not a
reasonable expectation, an interface to the database should be developed to
allow the user to modify the information without needing an understanding of
the database software or the database structure.
c The information that currently exists in the database is neither totally
accurate nor complete, nor is it from a wide range of sources. A basic meaning
for each word from only two different dictionaries has been entered into the
database to demonstrate Kamus' potential. The information has not been checked
for its level of compliance with Indonesia's language standards and no effort
was made to ensure that it included the different spellings that are available
for some words.
d The parser is dependent on the order that the affixes are retrieved from the
database in the sense that if there are two or more alternative decompositions
of a word Kamus will desist after detecting the "first" one.
e Kamus has only been developed for a UNIX system and uses an underlying Ingres
database.
f There is a limitation in Kamus in that if a word is not stored in the
database, the result of the parser cannot be guaranteed to be correct. It can,
however, make reasonably intelligent guesses in such circumstances.
There are many areas of improvements that can be made to Kamus; some to remove
the limitations previously identified and others to add extra features to
improve its functionality. The following is a list of the main areas:
a One of the first improvements should be to increase the vocabulary so that
not only does it contain all of the transitive verbs, but rather the majority
of the Indonesian language.
b An interface application program needs to be developed to allow the user to
modify the content of the database without needing to know how to operate the
underlying database software, or the database structure.
c For Kamus to have a practical use, it needs to be made available on other
computer operating systems and underlying database software.
d As Kamus is just a prototype for translating words, the possibility exists
that the program could be used as a basis for a larger and more sophisticated
translation system that translates whole sentences.
e Finally, as Kamus has been developed as an electronic tool for translating
Indonesian, there is no reason why it could not be adapted to be used to
translate other languages that exhibit a similar prefix-root-suffix structure.
Kamus is an experimental prototype that we believe has been successful in
acting as a combined electronic dictionary/thesaurus and grammatical analyser.
It provides a quick and easy tool for obtaining equivalent English meaning(s)
for Indonesian words. When Kamus is given a word a parser breaks it down into
its prefix, root and suffix, as appropriate. The database retriever then
retrieves the word's meaning, a list of synonyms and other grammatical
information such as the type of the word and its root, and a description of
the generic meaning produced when its affixes are joined together with that
particular type of root. Kamus will produce the correct results if the word is
in its supporting database (assuming that the information stored in the
database is correct), otherwise it will give an logical estimation of the
likely structure of the word. Kamus was developed in a UNIX environment with
an Ingres database supporting it. There are two interface environments, the
first being a windows style environment using X-Windows and Motif Widgets via
WCL and the second being a Unix command line environment.
At present, Kamus has been developed for translating Indonesian transitive
verbs, but there is no reason why the program cannot be developed further to
include the remainder of the Indonesian language.
During this project a computer assisted morphological analyser of Indonesian
transitive verbs was developed. Although it requires more work, it is believed
that what has been done is a positive step towards developing electronic tools
for use as translators between English and the languages of Australia's
neighbouring countries.
[EcSh89] ECHOLS, John M. and SHADILY, Hassan. Kamus Indonesia Inggris : An
Indonesian-English Dictionary. Cornell University Press, Jakarta, 1989.
[EcSh90] ECHOLS, John M. and SHADILY, Hassan. Kamus Inggris Indonesia : An
English-Indonesian Dictionary. Cornell University Press, Jakarta, 1990.
[John90] JOHNS, Yohanni. Bahasa Indonesia Book Two Second Edition Langkah
Baru: A New Approach. Australian National University Press, Rushcutters
Bay, 1990.
[JoSt89] JOHNS, Yohanni and STOKES, Robyn. Bahasa Indonesia Book One
Langkah Baru: A New Approach. Australian National University Press,
Rushcutters Bay, 1989.
[Kamu88] Kamus Besar Bahasa Indonesia (The Indonesian Large Dictionary).
Department of Education and Culture, Jakarta, 1988.
[MacD76] MACDONALD, Roderick Ross. Indonesian Reference Grammar.
Georgetown University Press, Washington DC, USA, 1976.
[Phil93] PHILLIPS, Robyn. Kamus: Computer Assisted Morphological Analysis of
Indonesian Transitive Verbs. BSc (Honours) thesis, Department of Computer
Science, University College, UNSW, Australian Defence Force Academy, Canberra,
Australia. October 1993.
[PoSu85a] PODO, Hadi and SULLIVAN, Joseph. Kamus Ungkapan Indonesia-Inggris
Jilid I A-L. Penerbit PT Gramedia, Jakarta, 1985.
[PoSu85b] PODO, Hadi and SULLIVAN, Joseph. Kamus Ungkapan Indonesia-Inggris
Jilid II M-Z. Penerbit PT Gramedia, Jakarta, 1985.
[ShSu88] SHIMURA, Masamichi and SUKMADJAJA, Darmawan. "An English-Indonesian
Computer Aided Translation System". Journal of Japanese Society for
Artificial Intelligence. Volume 3, Number 1, January 1988, pp103 - 107.
[Sukm88] SUKMADJAJA, D. "Building an Indonesian electronic dictionary".
International Symposium on electronic dictionaries - ISED '88. Inter
Group, Tokyo, 1988, pp76-68.
[Suda87] SUDARWO, I. "The need for MT in Indonesia". MT Machine
Translation summit. Manuscripts and Program. Japan, 1987, p113.
[Tsuj90] TSUJI, Yoshihide. "Multi-Language Translation System at Using
Interlingua for Asian Languages". Proceedings of an International
Conference organized by the IPSJ to Commemorate the 30th Anniversary.
IPSJ, 1990, pp 545 - 552.
A full word is a whole word consisting of the following syntax:
[prefix] + root + [suffix]
where the brackets indicate that the affix may or may not exist.
"Type of word" is the grammatical type of the full word. This may be, for
example, noun, transitive verb, adjective, etc.
"Type of root" is the grammatical type of the root. This may be, for example,
noun, transitive verb, adjective, etc. Note that words based on a particular
root do not necessarily have the same type as their root.
The prefix and suffix are the defined group of letters that may exist at the
beginning and end of the word respectively.
2 Department of Politics
University College, UNSW, Australian Defence Force Academy,
Canberra ACT 2600 Australia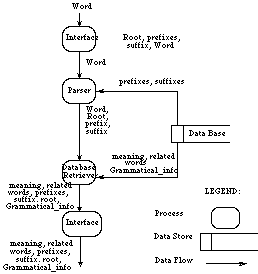 Figure 3: Data Flow Diagram - First Level
Figure 3: Data Flow Diagram - First Level
5.1 Parser
5.2 Database Retriever
5.3 Database
5.4 Words Stored in the
Database
6 Results of Kamus
7 Further Research
8 Conclusion
9 References
Annex A - Entity Relationship Diagram for the Kamus Database
 Entity Relationship Diagram for the Kamus Database
Entity Relationship Diagram for the Kamus DatabaseDefinitions of terms used in the Kamus entity relationship
diagram.
[1] Department
of Computer Science